


2. servereye Partnertag ein voller Erfolg – WIR SAGEN DANKE!
Bei sonnigem Wetter und in einer tollen Location fand am 30.06.2017 der zweite servereye Partnertag im big Eppel in Eppelborn statt. Partner aus ganz Deutschland kamen zusammen, um sich über die servereye Neuigkeiten, Entwicklungen, Visionen und Kooperationen zu informieren.
Neben Fachvorträgen von servereye, Docusnap, baramundi, pcvisit, HostPress, losstech, TANSS, Krämer IT und Securepoint konnten die Teilnehmer in lockerer Atmosphäre und zahlreichen Gesprächen in einer begleitenden Ausstellung untereinander fachsimpeln. Ein Highlight dieser Veranstaltung war die Keynote von Philip Semmelroth, der einen fantastischen Vortrag über servereye, inklusive kurzer Rap-Einlage, hielt.
Der persönliche Kontakt zu Partnern, die man bisher nur über Telefon oder E-Mail Kommunikation kannte, stand an diesem Tag ebenso im Vordergrund.
Als krönenden Abschluss eines durchweg gelungenen Partnertages ließen alle Beteiligten den Abend gemeinsam auf dem Krämer IT Sommerfest bei bester Laune, kühlen Getränken, saarländischem Grillgut und Musik ausklingen.
Auf diesem Wege möchten wir uns noch einmal bei allen Teilnehmern, ganz besonders den Herstellern bedanken, die diesen Tag zu einem tollen Ereignis gemacht haben.
Natürlich haben wir auch ein paar Fotos und Videos gemacht, die Sie sich hier ansehen können:
http://bilder.kraemer-it.de/ServerEye/2-Partnertag2017/
Ein schöner Tag geht zu Ende, doch eh man sich versieht, folgt der 3. Partnertag. Wir freuen uns auf Sie - bis zum nächsten Mal!
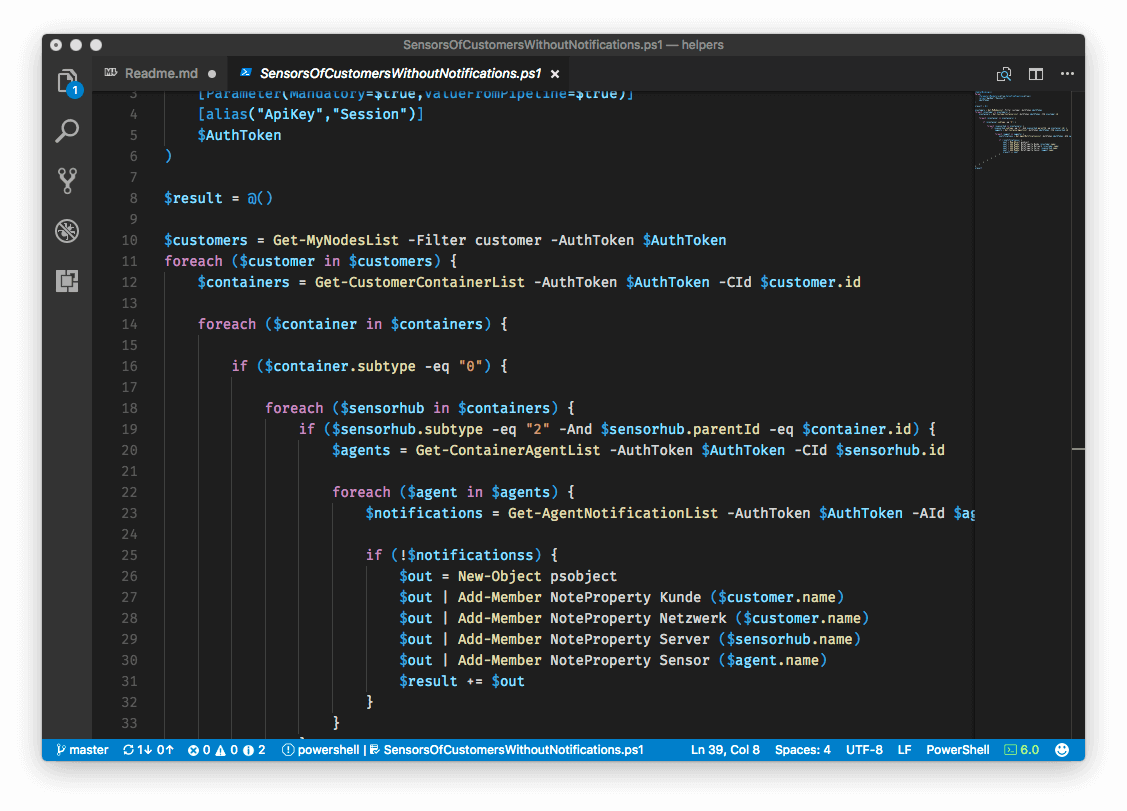
servereye einfach mit Skripten steuern
In der Microsoft Welt führt kein Weg mehr an der PowerShell vorbei. Sei es beim Konfigurieren des Exchange Servers oder beim schnellen Skripten von Routineaufgaben. PowerShell ist überall.
Die inzwischen in der Version 5 verfügbare Shell ersetzt nicht nur die betagte cmd.exe sondern ist integraler Bestandteil vieler Serverdienst. Als mein Kollege in unserer Skype for Business Telefonanlage die Wartemusik austauschen wollte, war das sogar nur über die PowerShell möglich. Auch die grafische Verwaltungsoberfläche von Exchange erstellt eigentlich nur Skripte die dann ausgeführt werden.
Für uns als IT Profis gilt es hier am Ball zu bleiben und sich die vielen Möglichkeiten zu Nutzen zu machen. Viele Routineaufgaben werden durch den Einsatz der PowerShell schneller, einfacher und sicherer. Wer es noch nicht gesehen hat kann sich ja mal die Software von unserem Partner ScriptRunner (https://www.scriptrunner.com/ ansehen. Hier gibt es schon viele vorgefertigte Skripte für alle möglichen Routineaufgaben.
Auch servereye selbst ist bereits von PowerShell durchdrungen, auch wenn Sie das vielleicht noch gar nicht gemerkt haben. Sei es unser Exchange Sensoren, die vmware Sensoren oder natürlich unser ActiveDirectory Sensoren, alle nutzen die PowerShell um ihr Aufgaben zu erfüllen.
Mehr Power für servereye
Mit dem Release des ServerEye.Powershell.Helper Modules gehen wir jetzt noch einen Schritt weiter. Wir geben die Ihnen die Möglichkeit via Remote PowerShell auf die volle Power von servereye zuzugreifen. Wir stellen unsere gesamte API als cmdlets zur Verfügung.
Sie wollen alle Kunden sehen?
Get-CustomerList -Session $session " Format-Table
Sie wollen eine neue servereye Gruppe anlegen?
New-Group -Session $session -Name "Server Techniker" -CustomerId 123-456-789
Oder einfach zählen in wie vielen Alarmierung Sie eingetragen sind?
Get-MyNotificationList -Session $session measure " %
Natürlich sind auch komplexere Abfragen möglich. Wie wäre es mit einer Liste aller Sensoren für die keine Alarmierung eingetragen ist?
https://github.com/servereye/helpers/tree/master/SensorsOfCustomersWithoutNotifications
Mit unserem neuen Helper Modul sind Ihren Möglichkeiten keine Grenzen gesetzt. Ein paar weitere Beispiele finden Sie unter: https://github.com/servereye/helpers/.
Wie das ganze Funktioniert und wie ich das ganze in meinen eigenen Skripten nutze steht hier: https://github.com/servereye/helpers/tree/master/ServerEye.Powershell.Helper.
Wir haben auch unsere API Dokumentation (https://api.server-eye.de angepasst. Zu jedem Eintrag finden Sie jetzt auch den passenden cmdlet Aufruf.
Und jetzt Sie
Sie haben bestimmt noch viele Ideen was man alles machen kann. Vielleicht schreiben Sie ja ein Skript, dass jeden Tag auf Facebook postet wieviele Backups Sie geprüft haben. Gerne veröffentlichen wir Ihre Skripte auf unserer Seite.
servereye mit Zwei-Faktor-Authentifizierung
Sicherheit nehmen wir sehr ernst. Aus diesem Grund steht ab dem 29.05.2017 auch die Zwei-Faktor-Authentifizierung für dein servereye Account zur Verfügung!
Die Zwei-Faktor-Authentifizierung ist eine optionale Sicherheitsfunktion, die wir vor allem Technikern empfehlen, die sich oft an fremden PCs anmelden. Bei diesen ist die Gefahr besonders groß, dass per Keylogger oder durch andere Tools das Passwort von dritter Stelle mitgelesen wird. Ist die Funktion aktiv wird bei jeder Anmeldung am OCC ein zeitbasierter, 6-stelliger Code abgefragt. Dieser Code wird im Normalfall von einer mobilen App generiert.

Jeder Benutzer kann die Sicherheitsoption selbst unter "Meine Einstellungen" aktivieren und deaktivieren. Wie bereits erwähnt wird eine mobile App oder jegliche Anwendung benötigt, welche das TOTP-Protokoll unterstützt. Eine genauere Erklärung und Auflistung findest du hier.
Alle FAQ-Artikel zur Two-Faktor-Authentifizierung haben wir für dich in einer eigenen Kategorie zusammengefasst.

Es ist zum Heulen – Der WannaCry Ransom-Wurm
Dieses Mal meldet sich das Security Monster zum Thema Ransomware. In den letzten Tagen hat eine neue Ransomware eine Welle der Zerstörung hinter sich hergezogen. Der Name „WannaCry“ bedeutet frei übersetzt „Es ist zum Heulen“.
Die WannaCry-Ransomware verbreitet sich über eine Schwachstelle im SMB-Protokoll von Windows, dem auf eigentlich allen Rechnern eingeschaltetem Dienst zur Dateifreigabe. Sobald ein Rechner in einem Netz infiziert wurde, verbreitet sich WannaCry als Wurm auf allen anderen erreichbaren und verwundbaren Windowssystemen. Dies macht diese Mischung aus Wurm und Ransomware so gefährlich, denn ist ein Rechner infiziert, dann sind es in kürzester Zeit alle.
Wie bei einer Ransomware üblich werden alle Daten auf den Systemen verschlüsselt und man erhält eine Meldung, dass man die Daten gegen Zahlung eines Lösegeldes entschlüsseln kann. Im Allgemeinen sollte man jedoch von dieser Zahlung absehen und die Daten selbst aus einem Backup wiederherstellen. (Ob man ein aktuelles Backup hat, kann man übrigens mit servereye leicht überwachen.)
Betroffen waren unter anderem die Systeme des NHS (National Health Service) aus Großbritannien, die Systeme der Telefónica (O2), das russische Innenministerium und die Deutschen Bahn. Unser Partner Avira hat Meldungen über die Infektion aus über 90 Ländern erhalten.
Gerade der fast totale Ausfall der NHS System hat das Leben von Menschen in Gefahr gebracht, da wichtige medizinische Daten nicht mehr einsehbar war.
Da sich WannaCry als Wurm verbreitet, sah sich sogar Microsoft gezwungen einen Patch für das seit Jahren nicht mehr unterstützte Windows XP zu veröffentlichen. (Link ist am Ende des Artikels)
Dies ist allerdings als absolute Ausnahme zu verstehen, auch ist nicht ausgeschlossen, dass dieser Notfall-Patch Nebenwirkungen unter Windows XP auslöst. Es gilt daher wie schon in den letzten Jahren, alle Windows XP Systeme die einen Netzwerkzugriff haben sollten durch ein neueres System ersetzt werden. Die Gefahr, die durch ungepatchte System ausgeht, ist zu groß.
Updates, Updates, Updates
Damit sind wir auch schon beim größten Problem, ungepatchte Systeme. Die Verbreitung über SMB basiert auf einer Lücke, die im Microsoft Patch MS17-010 vom 14. März 2017 geschlossen wurde. Das sind fast zwei Monate, in denen der Sicherheitspatch hätte eingespielt werden können.
Wir von servereye können an dieser Stelle nur nochmals auf die absolute Wichtigkeit von Sicherheitsupdates hinweisen. Das Einspielen alle Sicherheitspatches ist ebenso wichtig wie der Einsatz einer Anti-Virus Lösung. (Einige Sicherheitsexperten halten Updates sogar für wichtiger als Anti-Virus.)
Schalten Sie deshalb die automatischen Updates ein oder nutzen Sie ein Patch Management. (z.B. das von servereye https://www.servereye.de/smart-updates/)
Aktuell können wir zwar alle etwas aufatmen, da die Verbreitung durch den zufälligen Fund eines eingebauten Killswitches gestoppt wurde. Allerdings ist es nur eine Frage der Zeit bis die Autoren von WannaCry diesen Killswitch ausbauen oder ein anderer Wurm die gleiche Lücke ausnutzt. Spielen Sie deshalb noch heute alle Sicherheitsupdates ein!
Was ist mit unserer Anti-Ransom Lösung, hätte die einen Angriff nicht verhindert?
Ja und nein. Der Angriffsvektor war wie so oft eine E-Mail mit einem angehängtem PDF. Anti-Ransom kann diesen Fall abfangen. Sobald allerdings eine Maschine im lokalen Netz befallen ist, kann sich der Wurm auf allen anderen Systemen ausbreiten und wird nicht von Anti-Ransom gestoppt. Die im Wurm genutzte Lücke in der Windows SMB Implementierung bedeutet, dass hier ein Sperren mit Anti-Ransom nicht möglich war.
Die Kombination macht’s, eine erste solide Abwehr durch Anti-Ransom und das Blockieren der internen Verbreitung durch das Einspielen der Sicherheitspatches. Wie so oft ist Sicherheit ein komplexes Thema und erfordert Wachsamkeit in alle Richtungen.
Mit freundlichen Grüßen,
Ihr Security Monster.
PS: Wenn Sie unser Patchmanagement nutzen, sehen Sie den Einzelpatch MS17-010 nicht, dieser ist im kumulativen Update vom März enthalten (CU2017-03).
PPS: Wer das Sicherheitsupdate immer noch nicht eingespielt hat sollte das umgehend tun.
Für Windows Vista, 7, 8.1 und 10 sowie Windows Server 2008, 2012 und 2016
https://support.microsoft.com/de-de/help/4013389/title
Für Windows XP, 2003 und Windows 8
https://blogs.technet.microsoft.com/msrc/2017/05/12/customer-guidance-for-wannacrypt-attacks/
Dropbox ist schädlich für Systemhäuser
Cloudbleed, SHA-1 Kollision und andere Monster
Unser Team hat immer ein Auge auf die aktuelle Sicherheitslage im Internet. Wer wie wir die Nachrichten verfolgt hat, hat von zwei Vorfällen rund um Sicherheit gehört. Auf diese beiden Monster will ich etwas näher eingehen.
TL;DR: Die servereye Cloud Systeme sind von der Sicherheitslücke bei Cloudflare und der Kollision bei SHA-1 nicht betroffen.
Weiterlesen
Ausfallsicherheit der servereye Cloud
Am vergangenen Samstag kam es in unserer Cloud zu einem Failover Fall. Eine seit Jahren problemlos funktionierende, überwachte Komponente hat plötzlich den Dienst verweigert und somit Fehlalarme ausgelöst.
Bevor ich auf die genauen Umstände und unsere, teilweise automatischen, Reaktionen dazu eingehe, möchte ich die Gelegenheit nutzen und kurz den Aufbau unserer Cloud erklären.
Der Weg eines Alarms
Der Weg eines Alarms vom Kundensystem durch unsere Cloud und eventuell wieder zu Ihnen per Email zurück ist ein langer Weg durch etwa 15 eigenständige Komponenten.
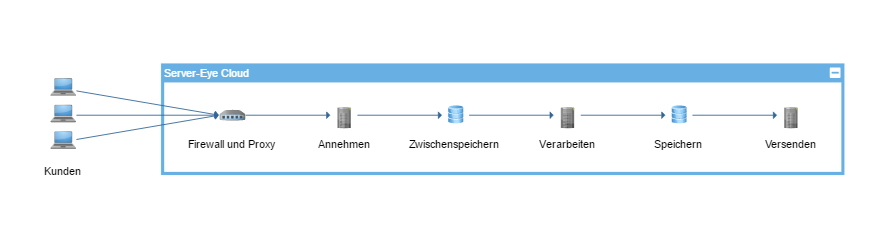
In dieser vereinfachten Ansicht sehen wir, dass die Daten Ihrer Kundensysteme und Ihrer eigenen bei uns im Rechenzentrum von einer Firewall angenommen werden. Die Verbindung wird danach direkt von einem Reverse Proxy übernommen, welcher das SSL terminiert und anhand verschiedener Kriterien die nächste Komponente für diese Daten festlegt.
Im Fall einer Alarmierung werden die Daten erst von einer Komponenten aus der Verbindung gelesen und zwischengespeichert. Die nächste Komponente greift dann ein, wertet die Daten aus und speichert sie in der Datenbank. Außerdem legt sie fest, ob ein Benutzer alarmiert werden muss, wie er alarmiert wird und auch wann. Auch das wird in der Datenbank eingetragen und abschließend von einer letzten Komponente ausgeführt.
Fällt eine dieser Komponenten aus steht der komplette Prozess. Um dies zu verhindern haben wir alle Prozesse von servereye redundant ausgelegt. In der Vergangenheit hatten wir alle unsere Komponenten in einem großen virtuellen Cluster mit mehreren Hosts. Komponenten konnten von einem Host auf den anderen geschoben werden, der Storage war ein Cluster Storage, etc. Mit der Zeit haben wir festgestellt, dass durch die komplette Virtualisierungsstruktur weitere Fallstricke und neue Probleme entstehen. Komponenten, die anderen Komponenten CPU Zeit stehlen, Performance Probleme des Netzwerkstorage und den Cluster Storage Services, etc. Unser Szenario mit mehreren 100 Maschinen, die permanent die gleiche Last tragen und kaum Spitzen in der Ressourcenauslastung haben, war einfach nicht ideal für diese Art von Virtualisierung.
Der jetzige Aufbau
Unser Anspruch war es daher das oben gezeigte simple Schaubild mit möglichst hoher Redundanz, Skalierbarkeit und einfacher Verwaltung umzusetzen. Dieses System verwenden wir nun seit etwas mehr als einem Jahr.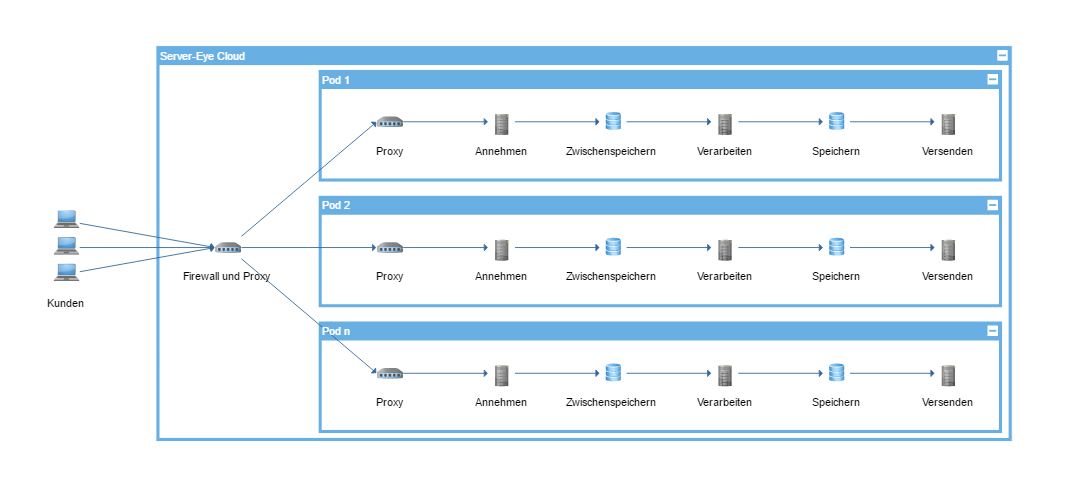
Ein Pod ist ein Virtualisierungshost und stellt alle Komponenten bereit, die servereye benötigt. Er enthält das OCC, API, Verarbeitung der Alarme, etc. Ein Pod bildet somit ein autark funktionierendes servereye ab. Wird ein Pod abgeschaltet oder funktioniert nicht beeinträchtigt dies nicht die anderen Pods. Komponenten müssen und können im Fehlerfall nicht auf einen anderen Pod umziehen. Es gibt keinen Netzwerkstorage mehr. Dies spart uns viel Overhead und Ressourcen ein, die vorher in Cloud Services und ähnliche verschwunden sind.
Die Firewall und der Reverse Proxy sind redundant vor die Pods geschaltet. Durch ein Source Balancing landet Ihr Kunde immer auf dem gleichen Pod. Dies erleichtert uns die Arbeit bei Support Fällen enorm, da zum Beispiel im Hilfebereich des OCC für Sie ersichtlich ist welchen Pod sie nutzen. Mit dieser Information können wir Problemen schneller auf die Spur kommen.
Müssen Wartungsarbeiten oder Updates durchgeführt werden lässt sich im Reverse Proxy einfach der entsprechende Pod abschalten. Die Verbindungen verteilen sich dadurch auf die anderen Pods um und es gibt nur noch sehr wenige Wartungsfenster, die tatsächlich die Funktionalität von servereye beeinträchtigen.
Zusätzlich lassen sich neue Technologien, Komponenten und Verbesserungen nun sehr leicht mit einem kleinen Kundenkreis temporär testen, bevor Sie auf den anderen Pods für alle ausgerollt werden.
Der Failover Fall
Es kann immer passieren, dass eine Komponente ausfällt, zu langsam arbeitet oder etwas unerwartetes passiert. Aus diesem Grund läuft auf jedem Pod ein eigenes Monitoring. Dieses Monitoring ist eine Eigenentwicklung speziell auf unsere Struktur angepasst. Es prüft verschiedene Szenarien, die auf einem Pod zu Problemen führen können und alarmiert immer die servereye falls eines der Szenarien eintritt. Der Reverse Proxy vor den Pods fragt regelmäßig die einzelnen Monitoring Systeme nach Ihrem Status und schaltet den Pod ab, falls der Status nicht zufriedenstellend ist.
Die alarmierten Techniker prüfen die involvierten Komponenten, beheben das Problem und schalten den Pod wieder aktiv. Der Failover Fall wird also voll automatisiert eingeleitet, immer die servereye Techniker informiert und manuell behoben.
Failover Szenarien und dieser Samstag
Wie erwähnt kam es diesen Samstag zu Fehlalarmen. Eine extrem zuverlässig arbeitende Komponente wird bereits seit langem überwacht und wird automatisiert gestartet, falls sie abstürzen sollte. In diesem Fall hat aber das Startscript, welches auch beim Serverstart ausgeführt wird, um die Komponenten zu starten, nicht mehr funktioniert. Dieses Szenario ist nicht über ein weiteres Monitoring abgedeckt. Dadurch griff das Monitoring mit dem Einleiten des Failover Falls erst nach wenigen Minuten, anstatt wie üblich nach ein paar Sekunden, ein. Durch den schnellen manuellen Eingriff konnte der Grund des Ausfalls schnell behoben und die Funktionalität nach kurzer Zeit wieder hergestellt werden.
Ergebnis
Die genauen Details, wieso die Komponente ausgefallen ist, befinden sich noch in der Analyse. Für uns ergibt sich aber vor allem die Erkenntnis, die man im Tagesgeschäft nicht immer wahrhaben möchte. Selbst die sicherste und zuverlässigste Komponente wird irgendwann ausfallen. Auch darauf sollte man vorbereitet sein und es im Idealfall vorher erkennen. Wir werden uns deshalb nochmals unsere Failover Szenarien ansehen und das Monitoring der einzelnen Komponente erweitern. Hätte das Monitoring diesen Fall sofort erkannt, hätten wir eher eingreifen können.
Bei Fragen zu unserer Cloud können Sie sich gerne jederzeit an uns wenden und eventuell hat der Artikel auch Ihnen ein paar Denkanstöße geliefert.

Und es geht schon wieder los!
Ab heute ist das servereye Team wieder mit der Wortmann Kinoroadshow unterwegs. Wir starten in Bad Oeynhausen und werden bis zum 09.03.2017 in 11 weiteren Städten in DeutschlandWeiterlesen